This blogpost is intended for a technical audience. In it, we cover:
- How model cards are currently used
- Syntactic and Semantic differences in their format
- Challenges with the lack of interoperability and a path forward
The term “Model Card” was coined by Mitchell et al. in the 2018 paper Model Cards for Model Reporting. At their core, Model Cards are the nutrition labels of the AI world, providing instructions and warnings for a trained model. When used, they can inform users about the uses and limitations of a model and support audit and transparency requirements. They have become increasingly popular with major organizations, including OpenAI, SalesForce and Nvidia, who have published them for Open-Source Models. Others have released tools to support creating Model Cards: Google, Amazon Sagemaker, Hugging Face and VerifyML.
Yet, despite seeming support for the Model Cards, there is little consistency both in terms of the content and format of these documents. With the increase in regulations requiring model disclosures, the lack of standardization will be an impediment for both internal reporting and importing/exporting of external models. In this blog post, we will review the main differences between popular Model Card tools and why standardizing reporting will be important in the world of AI Audits.
Format Matters
The Model Card examples we shared above were in Markdown, PDF and HTML formats. This visual representation is helpful for a developer deciding whether to use the model. But, it is less helpful when trying to produce a standardized report of their ML systems. This is even harder, when an organization is using third-party models and has to track down and organize reports stored in any number of formats. This will become increasingly burdensome when tracking model cards moves from simply being a best practice, and becomes required by regulation.
The toolkits produced by Google, Amazon and VerifyML do actually store the data in a JSON format, which is a step in the right direction, yet each toolkit uses a different schema for organizing the content. For example, while there is a general consensus that a card should report the “intended use” for a model, one would have to look in different locations to find it in each export. Amazon stores the information as a top-level field, while Google places it under considerations and calls it “use-cases”. We believe that a JSON Schema is the right format, but it needs to be interoperable across ML development environments.

Substantial Differences
The previous example is fairly simple, but the actual content is, also, different across examples and toolkits. For example, the “computational resources” and “environmental impact” of model training are only present in the HuggingFace Model Card tool. This field may not be useful when using a simple model or a pre-trained model, but having it represented in the schema can be important. For example, the EU AI Act Annex IV requires reporting “the computational resources used to develop, train, test and validate the AI system”. If the computational_resources field was in the JSON Schema, model developers would know where to put this information, and compliance teams would be able to gather this information reliably.
On a larger scale, VerifyML provides extensive support for Fairness and Explainability analysis, but does not provide a section for Model Training. In contrast, the Sagemaker tool has several explicit fields for tracking Model training procedure, but has just one vague field for Ethical Considerations. The appendix will further breakdown the differences between the different frameworks. Overall, while there is growing consensus that model cards are important, a clear standard for content has not emerged.
Portability Challenges
As organizations adopt overarching AI policies, it may be possible to pick one “schema” that represents their needs. Machine Learning developers will then be required to fill out this form for every internal model they create, and a script could import this data into the central AI Inventory.
However, organizations are becoming increasingly reliant on external models (whether it’s the next iteration of GPT or an industry-specific tool). Others are producing models meant for large scale open-sources or commercial use. Importing and exporting models has become a standardized process, whereas sharing Model Cards is a process of one-offs. Hugging Face has one of the largest repositories of open-source models, but their description can only be exported as Markdown annotated text that would require additional parsing.
As new regulations get passed, and organizations are required to report on external and internal resources, standard schemas will greatly accelerate the process. One would be able to “import” any Model Card into an AI Inventory with minimal additional work. Down the road, regulations could point to specific model card fields required for each clause.
Caveats and Conclusions
Each of the tools we reviewed has benefits and can be adopted as a first step, but model card creators should review the schema for gaps. In practice, one Model Card “tool” will never cover every organizations’ needs nor will creating a true universal standard be possible. Even if you take the super set of all known fields (and mark most as optional), there will be philosophical differences in how to report certain information. Do you just have one broad field for “Risks” or do you break it down into subfields based on common known risks? What does it actually mean to document “Explainability”? The same question may require different wording for a business leader and a developer. Different organizations will have different priorities based on internal policy and external regulations for their counties and fields (this guide provides excellent context for formulation Model Cards for your team).
Still, the current disparate state of Model Cards will bring around many difficulties for reporting and analysis. Going back to the nutrition label analogy, in the United States products have to be clearly marked as containing certain common allergens; If this information was obscured in the ingredient list or not present at all, there would be dangerous consequences for consumers. Even smaller design differences would make the shopping process a lot harder.
First, steps need to be taken to standardize fields that are mostly universal (we share our proposal in the appendix). Next, Model Card generating tools will need to align to this standard (Hugging Face, TensorflowHub and TorchHub are all missing a JSON style export right now).
Longer term, we see several exciting potentials around Model Card standardization:
- Regulation Mapping: When new regulations are created, they can be mapped directly to Model Card fields (either by the regulation creators or by independent groups)
- Model Card History: When fine-tuning of existing models, the developers can cite the existing model’s card as the source and add fields for the new features. This will create a change log and allow one to trace model lineage efficiently.
As AI regulations become omni-present, documentation will play an increasingly important factor. Creating better standards for Model Cards will make this process more efficient and effective.
—
Appendix
For this comparison we will compare fields from the Model Card Paper, Hugging Face Card Creator, AWS Sagemaker and VerifyML. In most cases, we will document a super-set of relevant fields. From a regulatory perspective, we will be referencing the NIST RMF Playbook.
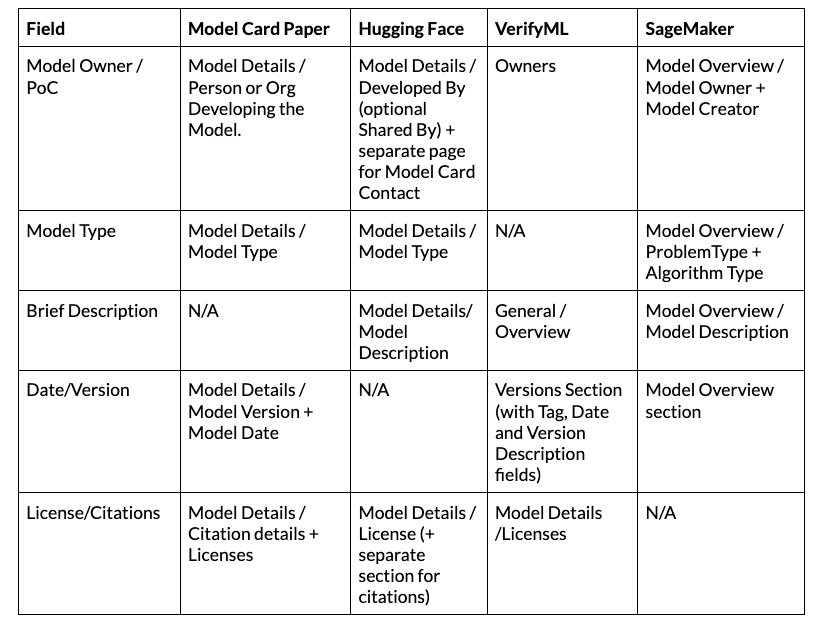
Model Basics
Basic information about the model is documented consistently across different frameworks.
Of note is the fact that while multiple frameworks reference “Model Type”, there is not a consistent set of classes for the type. This field could serve several purposes, either a very short description of the model for an external audience, or as an indicator for additional data to provide. It may be worthwhile to set a standard taxonomy of types and provide a separate short description field.
Note: We group Licenses+Citations and Date+Version in this table because they are closely related, in practice these can be broken out into separate fields.
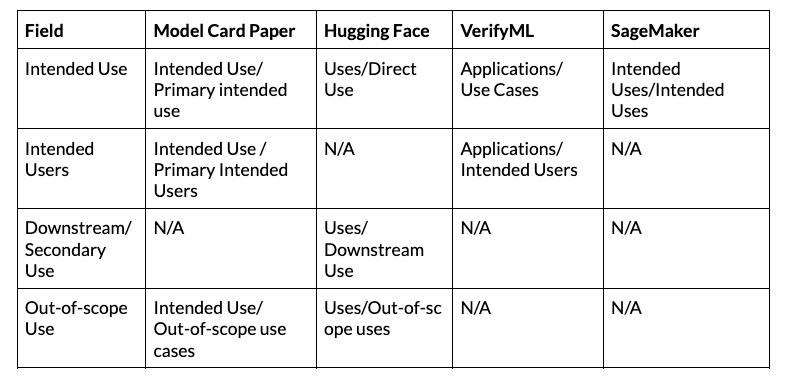
Intended Use
Intended use refers to how a model should and should not be used. This appears across all tools, but broken down in a different manner. This section is required under NIST MAP 1.1:
Intended purpose, potentially beneficial uses, context-specific laws, norms and expectations, and prospective settings in which the AI system will be deployed are understood and documented.
Training and Evaluation
This set of fields refers to various details of how the model was created and evaluated. Different sets of fields may be appropriate for different audiences (e.g a developer trying to recreate the model vs an end-user). Furthermore, certain details may be proprietary. NIST AI Risk Management Framework (RMF) focuses on the metrics (rather than the architecture):
- MEASURE 2.1: Test sets, metrics, and details about the tools used during test, evaluation, validation, and verification (TEVV) are documented.
- MAP 3.4 discusses metrics selection: “Processes for operator and practitioner proficiency with AI system performance and trustworthiness – and relevant technical standards and certifications – are defined, assessed and documented.”
- MAP 1.1 and 2.2 include references to limitations in model performance
Overall, NIST puts a larger focus on monitoring (e.g how will one ensure that the model continues to do well after deployment) and measuring risks (discussed separately). In contrast, the AI Act (Annex IV) does provide more explicit requirements including those in the fields below.
While all frameworks ask about the Datasets and Data Pre-processing, Datasheets could use a whole separate analysis that we will leave for another time.
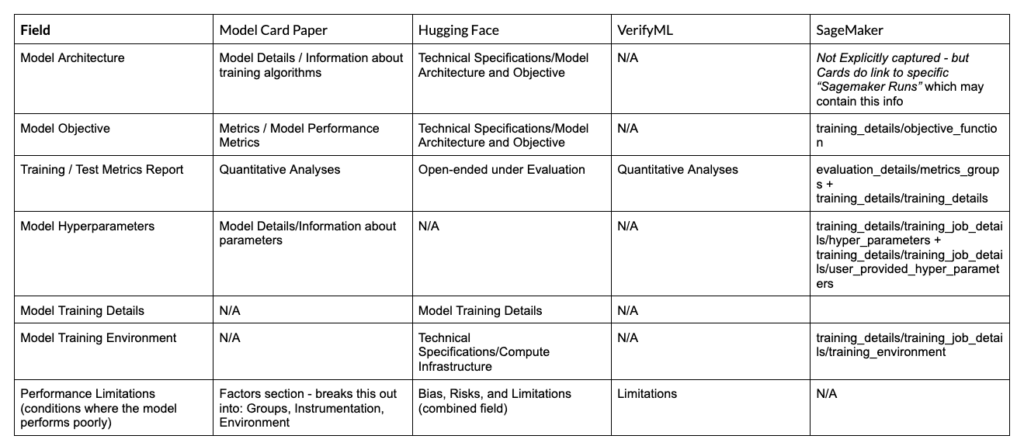
Notes:
- Model Objective refers to a specific short field that shows the target metric whereas “Model Metrics/Objective Justification” refers to a longer-form field discussing potential trade-offs
Risks and Ethical Considerations
Model Cards provide little guidance in this area, perhaps, because both concepts have subjective interpretations (and overlapping meanings.). Listing out specific risks may prevent the Model Card writer from considering other concerns. However, as new risk taxonomies emerge, we would like to see these fields subdivided further.
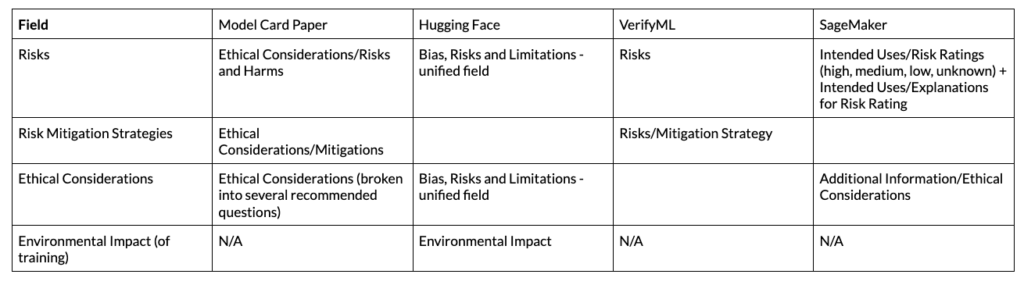
The NIST AI RMF extensively covers documenting and measuring risks. The most relevant section is MEASURE 1.1: Approaches and metrics for measurement of AI risks enumerated during the Map function are selected for implementation starting with the most significant AI risks. The risks or trustworthiness characteristics that will not – or cannot – be measured are properly documented.
Trustible Characteristics
For this section, we evaluate how characteristics of Trustworthy and Responsible AI are captured in the Model Cards. The characteristics are drawn from NIST AI RMF. Many of them are managed at the system level (i.e how the organization chooses to use this model), so this focuses on factors that are present at the model level.
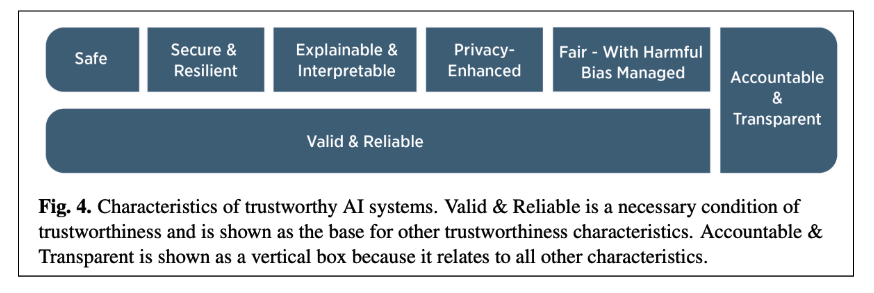
Image Source: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf
Each of these characteristics encompasses a broad range of factors, this analysis focuses on a narrower set of definitions. In the future, Model Cards can involve a more fine-grained set of fields for each characteristic, for now we analyze if the factors are mentioned at all.
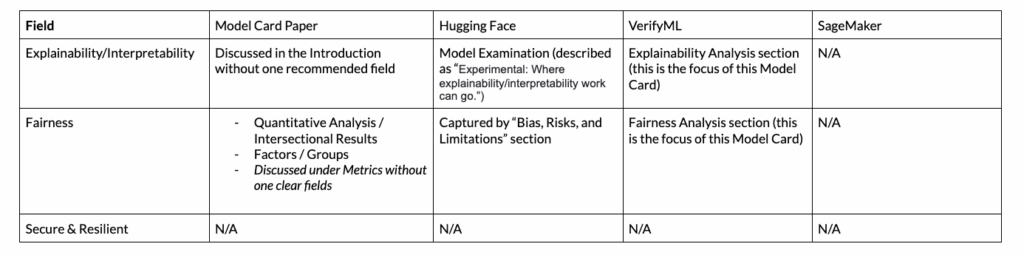
Fairness: Analysis of how a model performs in different (human) populations. What exactly is “fair” will depend on organization policy, but a Model Card should include the relevant analysis. For an overview of common metrics, consider this Medium Post and VerifyML’s fairness library.
Explainability/Interpretability: Analysis of how different inputs contributed to the Model Output. This can include analysis of features that contributed to individual decisions or features that are important overall. For a comprehensive summary of explainability approaches, review the IBM AI Explainability 360 package.
Secure & Resilient: Analysis of the model’s ability to withstand Adversarial Attacks. For example, for Image Classification this can include an analysis of how the model performs when random noise is added to the system. (Additional overview)