Updates include new models from OpenAI, Meta, Google, Anthropic, DeepSeek, and more; additional data evaluations; new regulatory and policy analysis; and more.
Generative AI models are transforming industries, driving innovation, and reshaping how organizations operate. Despite their wide-scale adoption, these models introduce risks to organizations given the limited transparency into their data, training, and operations. As AI adoption accelerates, leaders face complex decisions when selecting the right models, balancing performance with trust, safety, and compliance.
Last year, Trustible announced its research on Model Transparency Ratings dedicated to equipping organizational leaders with actionable insights into model risk attributes. By providing clarity on crucial factors such as data usage, risk assessment, model training methodology, and compliance with emerging regulations, our ratings empower organizations to confidently choose AI models aligned with their specific needs, ethical standards, and regulatory obligations.
Today, we’re excited to release Version 2.0 of our Model Transparency Ratings, which includes expanded and improved ratings criteria to address the rapid advancement with Generative AI models. We thank our customers and partners for their feedback.
What Is New?
- New Categories: Version 2.0 now includes 13 new categories and introduces a “Policy” section. While our old ratings were focused on the transparency requirements for foundation model developers under the EU AI Act, our new system takes a broader look at information that is important to users. The new Policy section includes categories on User Data and Incident Reporting – which can help organizations make decisions about which models are appropriate for their use cases.
- Updates to the Data Section: We included new categories that evaluate whether the developers discuss specific preprocessing requirements like “Toxic Data Handling” and “Data PII Handling”. While we had a broad “Preprocessing” category that evaluates how developers approached this process, our new Data categories tests whether the most important aspects of the data preparation process were handled. These updated Data insights will allow users to quickly evaluate the risk associated with the system.
- New Summary Ratings: We now review Evaluations for all models, because we believe that evaluation is important for models of all sizes. Our initial ratings only reviewed transparency around evaluations for models with Systemic Risk as defined under the EU AI Act (e.g. those that used 10^25 FLOPs or more during training). We have now created a separate “EU AI Act” Grade that is aligned with the requirements in the Act. We also introduce a rating that aligns with California’s proposed Artificial Intelligence Training Data Transparency Act.
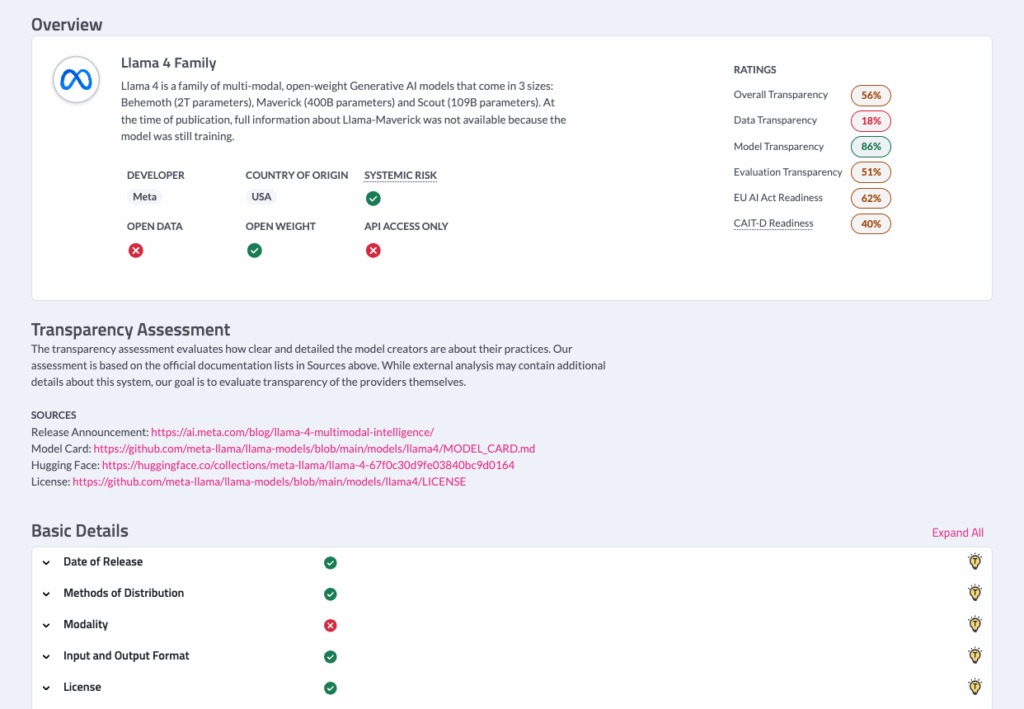
Example Model Transparency Rating for the recently released Llama 4 Family of Models from Meta
What Are We Seeing?
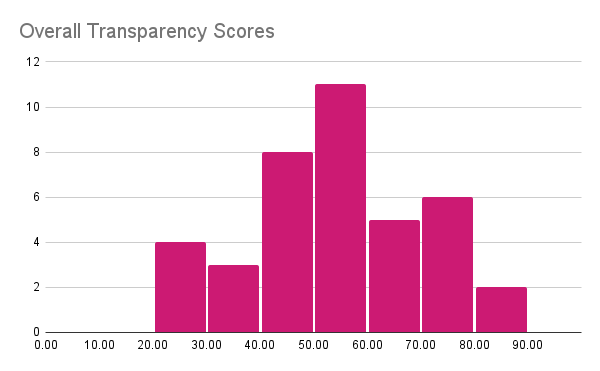
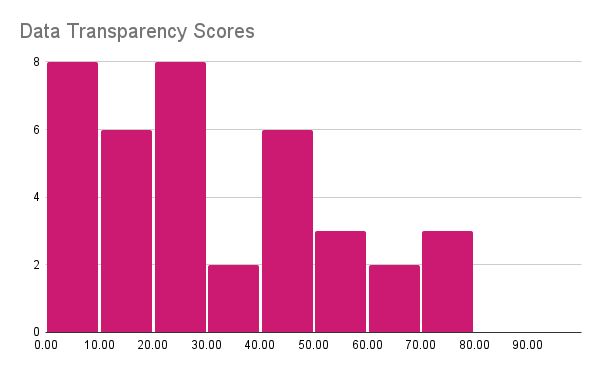
The four charts below show the distribution of overall scores and the main category scores. The overall scores are normally distributed near 50% showing that developers are about half open, providing many details about some things and omitting other topics. The Data Distribution is more concerning, many developers provide little to no information about the data; even the best ones do not disclose every detail. On Evaluation, the scores are higher because most developers will report benchmark performance (however few use public/reproducible tools) and mention the presence or lack of adversarial testing. Finally, the Model and Training category that tracks information about Model Design and Training does not show a consistent trend.
- Reduced Transparency over time: In general, we noticed that developers are less transparent with new model generations, especially as it relates to their Data. This is true across both open and closed weight models. For example, Gemini-1.5 received a 52% transparency rating, while Gemini 2 received only a 37% score (Graphic 2). Unfortunately, it is becoming status quo to release less information about the training data. We have seen this decline across most major model providers. Additionally, many developers will release the model before extended documentation or a report is ready. For example, our initial Llama-3 was much lower and we updated it when additional documentation became available at a later date (currently the newly released Llama-4 is below average, it remains to be seen if new information will be provided later).
- Data vs Evaluation Trade-off: No one model gets High ratings across all sections, although the OLMO models from AI2 come close. Developers release certain information, such as the data, weights, and code, but provide few details on the evaluation of limitations and risks. The OLMO models are disclosed as base models that need to be fine-tuned before further use. While our ratings account for this and do not expect models to perform alignment, we do expect a safety evaluation to give end users an understanding of the system as-is. Conversely, some providers (e.g. Anthropic) release an in-depth safety evaluation, but do not disclose information about the data. Recent research on emergent misalignment shows that fine-tuning models can remove built-in protections. Therefore, it is important to understand the contents of the original data to fully understand potential risks.
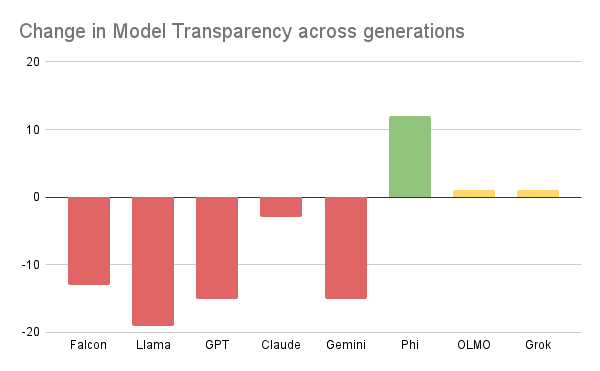
Change in Rating between the two most recent releases in the same model series. Many models have become less transparent over time.
What Is Next?
Our initial ratings system primarily focused on text-generation models and we are now turning our attention to image generator models. We do not expect our core categories to change, but we will explore certain nuances and make updates to the ratings as needed. We also plan to highlight the restricted uses for the models (e.g. can the outputs be used to train another model) to help users quickly assess what model is right for them. We would love to hear from you about the types of insights that you will find useful!
How to Use Trustible’s Model Transparency Ratings
Our ratings can be used to analyze the trends in the Generative AI ecosystem and to guide the development of AI systems that use these models. We support the latter in the following ways:
- Model Selection: The summaries provided in the ratings can help accelerate the model selection process by highlighting key details about the models. For example, our Policy section helps developers identify how their information is used, while the Data Sources rating helps developers review if the training data is appropriate for their task.
- Anticipating Mitigations: By reviewing the Data Preprocessing and Model Mitigations sections, developers can identify potential mitigations that need to be implemented when using the model. For example, they can identify whether the model is likely to generate toxic or biased content and prepare to build input/output guardrails.
About Trustible
Trustible is a leading technology provider of responsible AI governance. Its software platform enables legal/compliance and AI/ML teams to scale their AI Governance programs to help build trust, manage risk, and comply with regulations.
Graphical Analysis