

Models are the heart of an AI system and the source of many risks. With many developers now choosing to use external models instead of building them from scratch, it is important to be able to choose a model that both performs well and provides a clear understanding of potential risks. This can be challenging because provider documentation is inconsistent, can be spread across multiple model cards, technical reports, and/or legal pages, with no standard format. These reports are often long (200+ pages), highly technical (requiring deep technical AI expertise), and often omit key information necessary for assessing key risk areas. Deployers are left to de-code, decipher, and identify relevant information, with teams spending hours reviewing documentation and potentially missing critical information.
Trustible’s new Model Risk Assessment gives your team a structured, documented way to evaluate third-party models before you build on them. The assessment aims to:
- Solve a real, painful problem. Provider documentation is inconsistent, incomplete, and time-consuming to review;
- Address five distinct model risk areas. The assessment scores models across training data, architecture, evaluations, legal terms, and provider practices;
- Complement your use case and vendor assessments, not replace them. Vendor reviews don’t capture model-level differences, and use case assessments address deployment context, so the Model Risk Assessment fills the gap between the two.
- Tell you where to focus your own testing. Strong provider evaluation coverage gives you a baseline so your team can direct its own testing toward the areas where the provider is silent, rather than duplicating work that’s already been done.
Our team of AI/ML engineers reviewed publicly available documentation, resulting in a 37 question questionnaire scoring models on a standardized scale, producing both category-level and overall risk scores that allow side-by-side comparison of candidate models. The goal is to give AI deployers a structured, repeatable way to evaluate model-level risk before integration.
What The Assessment Covers
The assessment is designed to give deployers enough information to determine the risks of integrating or building with the model, and seeks to complement use-case level risk assessments. Trustible treats model risk as multidimensional: no single factor makes a model appropriate or inappropriate, however, gaps in any area can create downstream negative effects for the systems built on top of it. Common risk considerations include:
- Performance fit: Will the model perform adequately for the intended use case? A model not trained on Spanish-language data, for example, is a poor fit for a chatbot serving Spanish-speaking users.
- Safety: Does the model’s training and behavior raise safety concerns? A model trained on inappropriate content may not be suitable for applications that interact with minors.
- Legal compliance: Are there licensing or usage restrictions that affect the intended deployment? Some models prohibit commercial use or restrict specific application types.
- Provider reliability: Does the provider offer adequate long-term support? Providers that are inconsistent about documenting changes, deprecations, and security advisories can create downstream risks for deployed AI systems.
These concerns are not unique to model selection. Many surface in vendor assessments or use case evaluations as well. The Model Risk Assessment is designed to isolate the factors that are specific to individual models and that deployers need to evaluate before choosing one.
The Model Risk Assessment is designed to complement, not replace, Use Case and Vendor Risk Assessments. There is intentional overlap between the three, but each serves a different purpose. A model provider can be evaluated as a vendor, but vendor risk assessments don’t capture the specifics of individual models. The same provider can release models with meaningfully different risk profiles. Our Model Transparency Ratings have shown, for instance, that newer generations of models from the same provider often have reduced transparency around training data.
Model risks also inform use case risks, but use case assessments address a broader set of concerns around how a model is deployed and can account for mitigations that reduce model-level risks. Only the Model Risk Assessment goes deep on concerns that pertain to the model itself.
Organizations can take different approaches to incorporating the assessments. Vendor risk assessments are typically conducted early in the process by a team with legal and compliance expertise. Model assessments may be reviewed by cross-functional teams that involve technical and non-technical experts. Finally, use cases are reviewed by AI Governance committees that need to complete a comprehensive final review.
How the Categories and Questions Are Structured
We designed our five risk categories based on the most common concerns we hear from AI system developers. We also focused the assessment on topics that can be evaluated independent of use case and from public documentation alone. We didn’t want to penalize providers for protecting trade secrets.
The first four categories follow the model development lifecycle. This framing grounds the assessment in concrete stages where providers either do or don’t disclose information. Each question can be answered by examining what the provider has published, rather than requiring subjective judgment about potential harms.
- Collecting the data → Training Data Transparency
- Training the model → Model Architecture
- Evaluating the performance → Evaluation Coverage
- Releasing the system → Legal
The fifth and final category, Provider Practices, sits outside the lifecycle. Provider-level behaviors (governance policies, disclosure norms, support infrastructure) cut across every stage and affect the deployer’s long-term relationship with the model, not just its technical properties at a point in time. The provider’s public governance practices are a signal of their commitment to risk management.
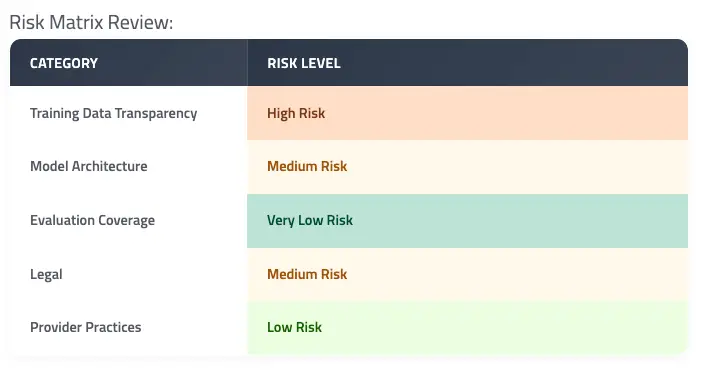
More broadly, the categories aren’t fully independent. A model can be trained on representative data but inadequately tested, or thoroughly evaluated on a poorly documented dataset. A provider’s strengths in one area don’t compensate for weaknesses in another. This is a pattern we see frequently with newer closed-source models: they often ship with detailed evaluation results but very limited training data disclosures. The category-level scoring is designed to surface these imbalances rather than let a single aggregate number obscure them.
Most questions are scored on three levels: No, Partial, or Full Disclosure.
- Partial disclosure corresponds to general statements acknowledging a practice without describing the methodology
- Full disclosure refers to detailed methodology. A provider stating that “PII was removed from the dataset” provides some assurance, but without knowledge of the methodology, a user cannot validate whether it was sufficient. A developer may have used a regex to remove emails and phone numbers, for instance, without addressing other categories of PII.
- No disclosure refers to our team not identifying information that would provide our team visibility into how the company manages that risk.
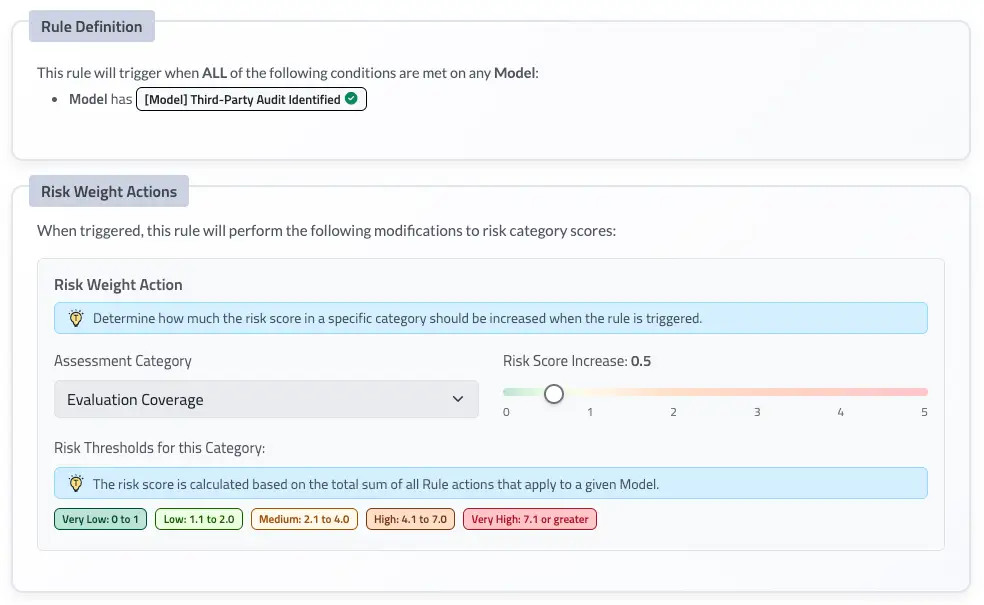
Similar to our use case risk model, risk is defined by attributes associated with question responses. The model risk model and weighting, is accessible via the Customization Center. Here is an example of how a Model Attribute informs the Assessment Category, Evaluation Coverage.
We’ve included Guidance for questions to facilitate teams’ understanding of how to best answer questions.

Below is an outline of how we define each risk category, which informs both the risk questionnaire and the guiding questions users will find within it.
Risk Category Details
Training Data Transparency
The training data used for a model is one of its biggest sources of capabilities, and limitations. For example, whether a model can generate code, translate text to French, or accurately respond about medical conditions are highly influenced by what data was used. Transparency about the training data is therefore important for calibrating model risk.
Our assessment starts with high-level questions about data sources and preprocessing, then addresses specific risk areas drawn from our Risk Taxonomy, such as inappropriate content and PII filtering. The focus is on transparency rather than prescribing specific practices. For some applications, it may be appropriate to retain data that would otherwise be filtered, such as a content moderation system that needs to recognize inappropriate content. With sufficient transparency, deployers can make informed judgments about whether the training data decisions are acceptable for their use case.
Model Architecture
The design of the model and how it was trained plays a big role in determining its safety and task-appropriateness. For example, a base LLM with no post-training will require additional work from the deployer to adapt it to a chatbot application. In addition, understanding the hardware and software requirements for a model helps developers rule out unsuitable models early in the development process.
Our assessment evaluates whether the provider discloses key architectural decisions, including model type, parameter count, training methodology, and post-training techniques or instruction tuning. It also covers practical deployment considerations: hardware requirements, supported inference configurations, and any known limitations that affect performance in specific settings. These details help deployers determine early whether a model is technically viable for their application before investing in deeper evaluation.
Evaluations Coverage
Deployers can test how models perform on their specific applications, but they may not be able to fully evaluate risks on their own. Running a prompt injection benchmark, for instance, can result in a ban from the provider, because it may look like an actual attempt to circumvent safety restrictions. Other evaluations may be expensive or complex, especially when conducted across a large set of candidate models. Strong evaluation coverage from the provider gives deployers a baseline understanding of model behaviors and lets them focus their own testing where it matters most.
Our assessment covers major risk areas, including bias, cybersecurity vulnerability, and safety, as well as the overall quality of the evaluation methodology. One key concern is reproducibility. Many providers report results on public benchmarks without specifying how those results were generated. For many models, even small details like prompt formatting can significantly affect performance. Thorough documentation of evaluation procedures serves as a signal of rigor, even when specific benchmark datasets are kept private. In those cases, providers can still release information about model settings and complement proprietary benchmarks with open-source ones.
We also consider whether human review was used to supplement automated evaluations, particularly where scoring relies on other models.
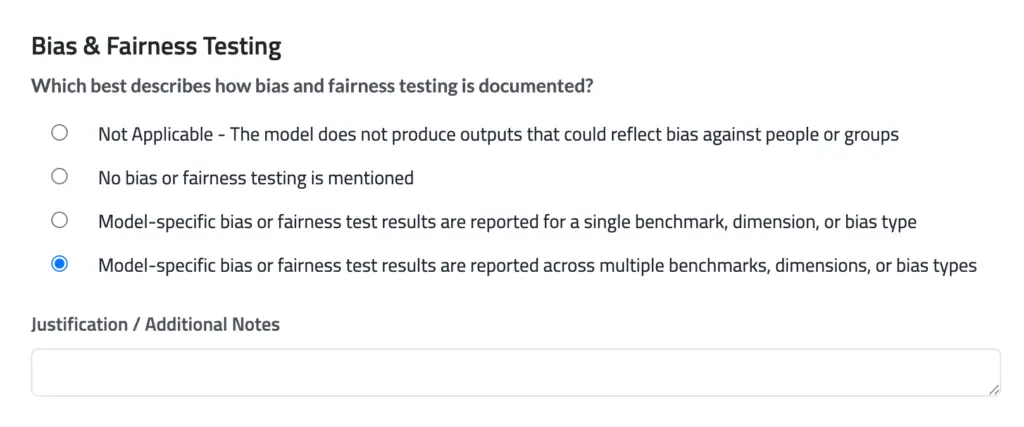
Scoring follows a three-tier system similar to the previous categories. For risk-specific questions, we aim to capture both breadth and depth. Bias testing, for example, requires benchmarks covering more than one dimension (such as race or gender) to qualify for the lowest risk tier. Reporting a table of results across multiple safety risks with no supporting context qualifies only for the middle tier.
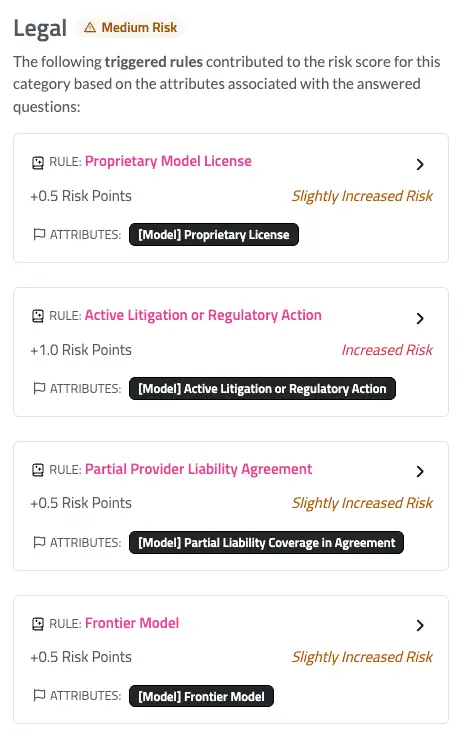
Legal
Beyond safety and performance, deployers need to understand the legal risks a model introduces. If a model’s behavior results in harm, deployers need to know where liability falls and whether the provider assumes any responsibility. A model trained on copyrighted data, for instance, may produce copyrighted material, increasing the deployer’s legal exposure.
Our assessment covers top-level legal concerns; for higher-risk models, an in-depth vendor assessment may be appropriate. The ratings consider both transparency and the substance of the legal terms. We look at standard contractual protections like indemnification, warranty, and liability limitations, as well as provider practices that may introduce risk, such as broad rights to use customer inputs for training.
A complete absence of legal risk isn’t realistic. A model with a restrictive license requires careful review to confirm that a use case fits within its terms. A fully open-source model, on the other hand, provides maximum flexibility but typically offers no liability protections. The assessment is designed to surface these tradeoffs, not to declare one licensing model safer than another. To see the attributes that inform the risk score, click on the Trustible lightbulb.
Provider Practices
The first four categories address risks tied to specific stages of model development. It is also important to consider provider practices and how they conduct business at an organizational level. Clear communication about model changes and discovered vulnerabilities reduce risk for deployed systems. Detailed responsible AI policies help deployers assess whether a provider’s principles align with their own.
Our assessment covers three areas: communication, support, and governance. For communication, we evaluate both how users can submit feedback (general questions, bug reports, vulnerability disclosures) and how the organization communicates outward, including change logs, deprecation notices, and incident disclosures. For support, we assess the availability of dedicated support channels and service-level agreements. Applications with high availability requirements benefit from providers that offer formal uptime commitments. For governance, we consider best practices for AI developers: detailed responsible AI principles, compliance with voluntary or formal frameworks, and reporting on environmental impact.
As with the Legal category, we consider both transparency and substance. Many open-source models are released by academic institutions with fewer resources for formal support infrastructure, but their open nature can make them more transparent in other ways. To account for this, we introduce some scoring adjustments for open versus proprietary models.
Model Risk Assessment Limitations
The Trustible Model Risk Assessment covers a broad range of risks associated with third-party models, yet it has boundaries. All questions are answered from publicly available documentation, which may not fully reflect the provider’s practices, particularly around evaluation coverage. Providers may share additional confidential information with customers and regulators that would change their risk posture. The assessment captures what a deployer can verify independently, not the full scope of what a provider may be doing internally.
The assessment also focuses on the model itself, not the model in context. The same model may be more or less risky depending on the application. Permissive policies about how the provider uses input data, for example, may matter less if no personal or confidential data is sent to the model. To properly assess risk, a use case-level evaluation should account for the specific inputs, outputs, and broader sociotechnical context of the deployment.
Conclusion
The Model Risk Assessment is one piece of a broader evaluation process, but it addresses a gap that most organizations are currently filling with ad hoc research and inconsistent methodologies. A structured, repeatable approach to model-level risk makes it easier to compare options, document decisions, and identify concerns before they become problems in production.